为什么要关心内存模型
内存模型是一个约定或者规则, 是体系结构决定的,定义了内存的某些属性和行为。 一般各个架构之间有所不同,比如 ARM 会做合并访存、乱序执行这类优化方法。
所以,某些情况下,指令的执行顺序可能不与你程序设计的一模一样,只是为你呈现的结果相同罢了。 当然这里边还有编译器来优化(捣乱 hh)。
一般程序无需关心内存模型带来的差异,除非你从事底层软件开发(嵌入式开发)这种需要和寄存器打交道, 涉及系统底层机制的实现时,你必须按照内存模型来合理的规划你的程序。
各种内存模型
不同的处理器架构有不同的内存模型.
- 例如, ARM 架构可能优化内存读写指令的顺序, 但是 X86/64 架构通常不会这样做.
- X86 架构的每次内存加载指令都带有 acquire 语义, 每次写内存都带有 release 语义. ARM 架构就不一定, 拿 ARMv8 来说, 仅有
LDRA/STRL指令带有此含义.
我们称类似 ARM 架构行为的内存模型为 Relaxed Memory Model
将 X86/64 上稳定运行的 Lock-free 的代码搬到 ARM 上, 就不一定是可行的.
顺序一致性模型 Sequential Consistency Model
指令的执行顺序总是和可执行文件一致.不论是否存在内存访问指令重排等优化操作.
举个例子,
- 先写后读内存的模型中, 总是能实现读内存时值是新的(不会被优化成先读后写).
- 多条
ldr指令的执行顺序也是严格按照程序所写
多处理器环境下, 每个核的执行顺序都是可执行文件中的指令顺序. 多核之间的同步需要程序员来保证.
宽松一致性模型 Relaxed Consistency Model
各种优化 buff 叠满,一般加载/存储指令的执行顺序不能保证,需要程序员自行维护。
这种宽泛的规则,给了处理器很大自主决定空间,它可以根据当前的情况决定是不是如何处理你的访存指令。
宽松内存模型下几种保证正确性措施
“volatile” 关键字
这里对
volatile的描述都是基于 C 语言的.volatile(JAVA) != volatile(C/C++)
volatile(JAVA) == atomic(C/C++)
volatile解决的是编译器的过度优化问题,
添加了volatile关键字表示该变量可能随时被改变, 即便当前的程序中没有体现,
也可能被其他的线程修改,或者对于寄存器来说自身就会发生变化。
对于添加volatile关键字的变量, 编译器会严格按照你所写的来编译:
- 不会删除内存分配
- 不会在寄存器中缓存变量, 每次访问都会重新读内存.
- 不会改变赋值的顺序
看一个未添加volatile关键字可能导致的问题: 下面是一个简单的函数, 作用是为在等到设备完成当前任务后关闭设备.
void poweroff(dev_t ID, reg_addr_t *busy) {
while(*busy)
;
poweroff();
}
看上去似乎是正确的, 但"过于聪明"的编译器可能让这段程序失效. 编译器总认为我们的程序是单线程的, 即没有人会来修改busy. 这种过分的优化导致汇编的结果仅仅读busy一次, 然后陷入死循环. 显然不是我们想要的.
void poweroff(dev_t ID, reg_addr_t *busy) {
if (busy) do_endless_while();
poweroff();
}
对关键的busy变量添加volatile关键字将拯救我们!
void poweroff(dev_t ID, reg_addr_t volatile *busy) {
while(busy)
;
poweroff();
}
延申阅读材料: 为什么大部分情况下使用
volatile关键字都是错误的. 只要锁正确实现, 那么被锁锁住的变量就完全不需要volatile来声明, 因为获得锁时其他的 core 不能修改它. 这是锁来保证的, 不应该添加多次一举的 volatile!Why the “volatile” type class should not be used — The Linux Kernel documentation
内敛汇编中的 volatile
asm volatile("":::"memory");
volatile向编译器说明禁止内敛的语句与其他语句 reorder。但不能保证内部 reorder, 那是下面内存屏障的任务"memory"向编译器说明对于所有内存访问操作,不能使用 asm 之前预加载到寄存器中的值 ,而必须在 asm 内部重新加载。保证其内部访问内存值具有可见性和正确性。
内存屏障 Memory Barrier
对于可执行文件中的指令顺序, CPU并不会严格的依次执行, 而是进行更底层的"优化"来保证高效率, 即CPU乱序执行(Out of order)。 内存屏障指令能够保证乱序执行不会跨过该指令。
正如下面的例子, 两条指令之间没有数据相关, 所以指令执行的顺序是不确定的.
ldr [x1], x2 # load x2 -> *x1
str x3, [x4] # store *x4 -> x3
而在指令中间插入一条内存屏障指令, 就能强制保证内存屏障指令后面的指令不能先于其前面的指令执行.
ldr [x1], x2 # load x2 -> *x1
# An Memory Barrier Instruction
str x3, [x4] # store *x4 -> x3
AArch64 内存屏障指令
AArch64 提供了三种类型的屏障指令, 其中DMB和DSB属于内存屏障指令:
- ISB(指令同步屏障)
- DMB(数据内存屏障)
- DSB(数据同步屏障)
ISB
字面翻译为指令同步, 执行后指令流水线被刷新, 后续的指令需要再次fetch. 实际上可以理解为上下文同步. ARMv8将上下文定义为系统寄存器的状态, 并将上下文更改操作定义为: Cache, TLB和分支预测器的维护操作, 或对系统寄存器的修改.
这些上下文更改操作对其后的指令来说并不是立即可见的. 只有在发生上上下文同步事件之后才可见. 所有的上下文同步事件包括:
- 发生异常
- 异常返回
- 执行
ISB指令
所以ISB的作用可以表示为: 同步ISB前面的上下文更改操作, 并刷新指令流水线, 确保后面的指令可见新的上下文.
所有的上下文更改后都需要添加ISB指令来保证后续指令执行时, 更改操作已经完成. The following example shows how to enable the floating-point unit and SIMD, which you can do in AArch64 by writing to bit [20] of the CPACR_EL1 register. The ISB is a context synchronization event that guarantees that the enable is complete before any subsequent FPU or NEON instructions are executed.
MRS X1, CPACR_EL1 // Copy contents of CPACR to X1
ORR X1, X1, #(0x3 << 20) // Write to bit 20 of X1. (Enable FPU and SIMD)
MSR CPACR_EL1, X1 // Write contents of X1 to CPACR
ISB
This does not mean that an ISB is required after each instruction that modifies a processor register. For example, reads or writes to PSTATE fields, ELRs, SPs, and SPSRs always occur in program order relative to other instructions.
DMB
内存屏障指令ARM的实现, 上面已经介绍过. 这里再给出一个例子:
LDR X0, [X1] // Must be seen by the memory system before the
// STR below.
DMB ISHLD
ADD X2, #1 // May be executed before or after the memory
// system sees LDR.
STR X3, [X4] // Must be seen by the memory system after the
// LDR above.
DSB
在DMB的基础上进一步阻止除了内存读/写外的其他指令. 如下示例保证DC的执行结果为ADD操作可见。
其后可以跟SEV指令, 它将等待此处理器发出的所有Cache、TLB和分支预测器维护操作完成.
DC ISW, X5 // operation must have completed before DSB can
// complete STR
STR X0, [X1] // Access must have completed before DSB can complete
DSB ISH
ADD X2, X2, #3 // Cannot be executed until DSB completes
从上面的例子中可以看到,DMB和DSB指令接受一个参数, 用来指定生效的地址区域.
单向屏障指令 LDAR/STLR
上面介绍的屏障指令能够保证,: 程序中所有在屏障前面的内存访问在执行屏障指令之前那一刻对于所有的master都是可见的(visible). 说中国话就是指定内存域(通过屏障指令的参数指定)的访存指令不能够跨过屏障指令而乱序执行.
+----------+
| LOAD +<--+
+----------+ | valid reorder
| STORE +<--+
+----------+
| DMB |
+----------+
| LOAD +<--+
+----------+ | valid reorder
| LOAD +<--+
+----------+
+----------+
| LOAD +<--+
+----------+ |
| STORE | |
+----------+ | invalid reorder
| DMB | |
+----------+ |
| LOAD | |
+----------+ |
| LOAD +<--+
+----------+
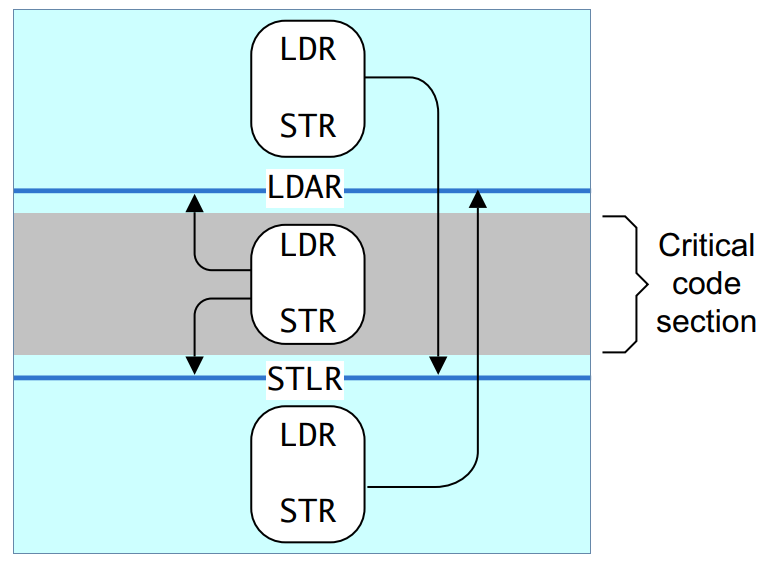
然而, 这种双向的barrier太过于严格, 以致于导致不少性能的损失. 所以, ARMv8提供给我们单向的内存屏障指令, LDAR/STLR
Load-Acquire (LDAR)
限制程序中所有在LDAR指令之后的内存访问必须在执行完该LDAR指令后才对其他master可见.
用中国话说就是程序中所有在LDAR之后指令的内存访问都不能被execution-reorder到LDAR之前.
再通俗点, 就是仅仅设定了一个reorder的上限.
Store-Release(STLR)
可以对比LDAR, 限制程序中所有在STLR之前的访存操作必须在执行STLR之前就对其他master可见, 不能再往后延迟了, 通俗点说就是设置了reorder的下限.
用一张ARM用户编程手册中的图来解释, 黑色箭头代表每条指令最远能够reorder的路径.