CISC 的发展到 RISC 诞生
- 1940-1950
- 冯诺依曼架构被提出:以存储器为中心,软件和硬件的设计分离,减少了系统中的硬连接,实现了可编程的计算机!
- 用户程序(二进制指令)被存储到存储器中。存储器的容量,几 k 字,不能放下很大的程序。
- 存储器有 CRT 磷光线存储器(支持随机存储),磁芯(Core memory)(磁芯存储:统治存储领域 20 年 - 知乎)。
- 1960-1970
- PDP-6 典型设计,16 个通用寄存器,SP+FP,ISA 逐渐变得复杂
- 此时人们用汇编指令写程序,认为每个常见操作都应该实现为一条特殊的指令(三角函数、CRC…)。(???与 ROM 和 RAM 的速度差异有关吗)
- 这么多种类的指令硬连线的方式太复杂 ==> 微码
- 微码 ROM 是一张表:ISA 指令和微操作之间的映射,一条指令对应多个微操作
- 有了微码,创造一条新的指令很容易,使用不同微操作的组合即可
- 1980
- 高级语言和编译器来了,不用再手写指令
- 编译器很难利用到这么多复杂的指令,生成的汇编代码常用几条指令占 95%,大量的不常用指令占据了微码 ROM。
- 发明出基于 Mos 的 SRAM,比原先的快 2-10 倍!???所以呢
- CISC 不适合与流水线
- decode 时间不一致,边 decode 边取指,不确定的时间段
- 寻址模式多,容易引发数据竞争,而且不容易检测
流水线 Pipeline
RISC 的架构中出现的,旨在提高处理器处理效率,争取在一个时钟周期中完成一条指令(CPI=1)。
CPI指标的意义
CPI 总是衡量大量指令的平均结果,单讨论一两个指令的 CPI 是没有意义的
Pipeline CPI 计算:从第一条指令结束到最后一条指令结束的周期数/指令数
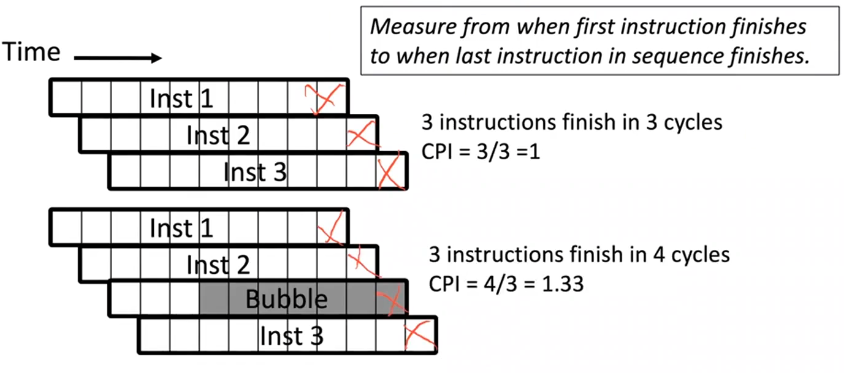
 PS:为什么不从第一条指令的开始进行计算?==> 因为通常有大量的指令(百万),所以第一条指令开始到结束的时间段没什么实际意义,影响不大。
最经典的当属 MIPS(无内部互锁的流水线处理器)的五级流水线技术。MIPS 体系结构本身就是为了流水线而设计的,每条指令的执行过程都分成五级。每一级成为一个流水线阶段,每个阶段占用固定的时间,通常是一个时钟周期。
像是取指、访存阶段都比较耗时,超过了一个时钟周期。
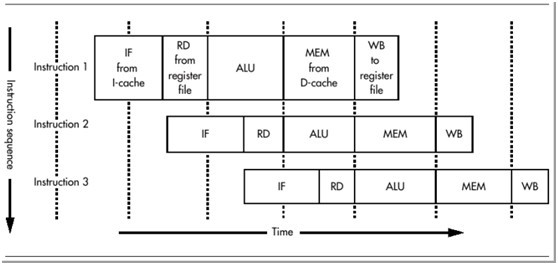
有的微架构就使用超长的流水线(多级),将指令阶段进一步细分,有助于增加并行度。 但是呢,阶段分的太细,在微架构层面会比较复杂,因为各个阶段之间需要发送信号,会浪费一些时间。
数据竞争的三种解决方案
- 等待。其他竞争的指令等着当前指令执行完再执行。
- Bypass。需要额外硬件,
- 预测。需要额外硬件,先猜一个值,如果错了再刷新流水线重退。
异常 Exception
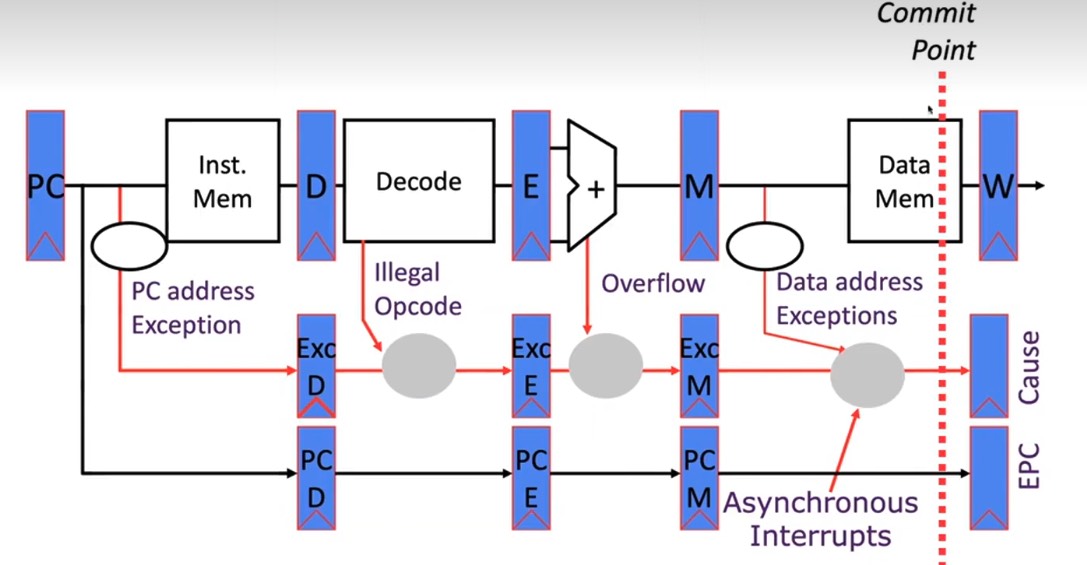
流水线的各个阶段都会产生异常,怎么设计?
难道在每个时钟周期都检测流水线中有无异常吗?显然不行,因为假设指令 B 在 Decode 阶段产生了异常,如果此时就认定指令 B 触发异常。但殊不知上一条指令 A 会在回写阶段也触发异常。 而一般来说,按照程序员的视角我们认为指令一条一条的执行,所以也希望异常按照指令顺序产生。
进而,就提出了在流水线的最后【提交】阶段才检查异常。
- 流水线中多了 3 个额外的寄存器用于标记每个阶段是否产生异常。
- 前面指令产生的异常标记可以覆盖后面指令。这就使得异常按照指令顺序产生。
- 若一条指令在前面阶段已经产生异常,后续阶段 Bubble。
- 在最后提交阶段之前,会检查是不是有异常或者异步中断?(如果两者都有,实现定义)之后下一个 PC 就是异常向量。
内存 Memory
Core memory 是首个大标量可靠存储器。
- 1940s 被提出
- 可靠,比半导体存储器可靠的多
- 手工制造,产量低
- 访问时间 1 微秒
半导体内存从 1970s 开始
- 英特尔最早的主要产品是半导体存储器
最早的半导体存储器是静态 RAM,Static RAM
- 持续通电,但不需要刷新
DRAM 最早是 IBM 的一个人发明的,但是由英特尔做到商业化
- 电容来存储 bit
预取 Prefetching
现代处理器一个时钟周期内可以同时处理多条指令,甚至每个周期执行 ldr/str 操作多次。
指令预取
Basic Schemes:简单地预期 program order 下的 N 行
很简单就不说了,在 1 条指令 miss 的时候,预期下面 N 个 cacheline 长度的指令。
Basic Schemes:启发式的错误路径预取
当 decode 到一条条件分支指令后,就立马预取跳转和不跳转两条方向上的指令。
- 可能性总>0,每个分支总在某种情况下会发生。
- 【Challenge】立即跳转指令来说,可能预取是来不及的。
- 【Challenge】某些条件跳转不能支持,例如寄存器间接等,你无法第一时间知道目标地址。
更加高级:与分支预测单元结合,预期分支预测结果方向的指令
使用 Non-blocking Cache 来增加 Cache 带宽
- Non-blocking cache or lockup-free cache 允许 cache 在处理上一个 miss 时继续支持后续指令的 cache 命中。
- 甚至可以维持若干次的 miss(现代处理器一般是 10 几次)
动态加载动态链接在虚拟地址出现之前就已经被广泛使用了,它正是用于解决程序库中的物理内存地址不能写死。
后面,因为 IO 很慢,只运行一个程序的话 CPU 会一直等待着。这就促使多程序并发思想的诞生。每个用户程序占用物理内存的一部分,只允许访问这些。为每个用户程序分配的内存空间也叫 Segment,如果 OS 检测到超出了,会报 Segment Fault。
这种分段的方式慢慢显示出了它的问题:外部碎片。为用户程序分配的段必须在物理上是连续的。除此之外,如果程序在运行时想动态的扩大自己的段也是比较困难的。
段分配的缺点诞生了虚拟内存+分页:
- 物理上不需要连续了。
TLB Miss 的处理分为软件和硬件两种方式:
- 软件(MIPS、Alpha)。TLB Miss 触发异常,由 OS 走一个 PTW 来填充 TLB 表项。非常耗时,因为对于 OOO 的处理器,必须刷新 pipeline 去走到异常处理程序中。而且现代的处理器一个周期内可以并行做几个翻译,用软件的方式实在是效率太低。
- MMU 去做 PTW,然后重填 TLB。
567 的总结
- 首先介绍了内存是怎么回事,物理形态的发展历程。
- 纸带 -> 磁芯存储(Core Mem)-> 半导体存储
- 随后介绍了 Cache,解决了内存和 CPU 之间数据交换速度差的问题。
- Cache 很好,但是一旦 miss 造成的损耗还是太大。预取 prefetch 可以帮助解决一些问题。既然你已经 Miss 已经要访问内存了,何不根据某种预测算法多取一些,尽量避免以后发生 Miss 的概率。设计好的预取算法是很关键的。
- 预取包括:指令预取和数据预取。
89 的总结
- 之前所有的讨论还是基于单任务的情况
- 我们写了很多程序在 CPU 上运行,有些代码段是通用的,程序员们就把他们做成了库封装起来。
- 代码直接访问物理地址,所以这些库目标文件中的物理地址不能写死,产生了动态加载动态链接的技术,解决库在不同机器上运行的问题。
- 还有一个问题就是 IO 很慢,只运行一个程序的话 CPU 会一直等待着。这就促使多程序并发思想的诞生。每个用户程序占用物理内存的一部分,只允许访问这些。为每个用户程序分配的内存空间也叫 Segment,如果 OS 检测到超出了,会报 Segment Fault。 也就是分段的思想。
- 分段有缺点:外部碎片且不能动态扩展。
- 分段的缺点引出了虚拟内存+分页的技术,每个应用程序的内存在物理上不再需要连续。
- 虚拟内存+分页就要使用页表,最开始的页表是单级的,一个 entry 映射一个页面。如果映射所有的虚拟空间会导致页表很大,但这种单级页表又没办法拆开映射,于是就有了多级页表。
- 多级页表查询耗时,在物理上就有了两个优化:
- TLB 缓存页表的映射信息。
- 对大页 Huge page 的支持。
- TLB Miss 之后的 refill 一开始是软件实现的,发生 Miss 之后 CPU trap 到特殊的 refill handler,在里面作 pagetable walk,然后用处理器提供的特殊指令重填 TLB。
- 然而这种方式随着处理器设计的提升变得影响性能,CPU 可能在一个时钟周期内并行的有多次内存访问,软件处理的效率太低。
CPU 流水线如何适应有 TLB 的虚拟内存翻译
加入 TLB 虚拟内存之后,在进入访存前 额外多了一些地址翻译的电路连线,在流水线中,我们如何解决这个更加延长的访存阶段呢?
- 降低 CPU 时钟频率?时钟周期长了,就延长了访存阶段的时间。但是对性能的影响是无法被接受。
- 为地址翻译增加额外的独立流水线阶段?也就是增加流水线的级数,增大了 CPI
- 虚拟地址 Cache。在查询 Cache 前就不需要地址翻译了,如果 Cache Miss,才走地址翻译,
- TLB 和 Cache 并行查询,这是现代处理器常用的套路。
接下来讲就最后两点分别展开介绍。
虚拟地址 Cache
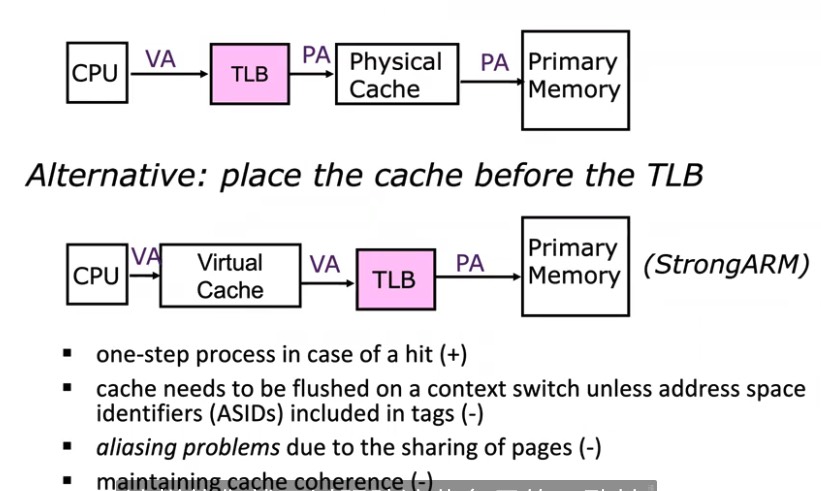
几个特点:
- 会带来 aliasing 问题,一个上下文内也会有 多个虚拟地址 映射到 同一个物理地址的共享情况。这时候一旦一个修改了,另一个会不知道。
- 更多的Cache coherence问题,多核之间的,一旦一个CPU更新了某个物理地址,不太方便通知到其他核心,要做物理->虚拟的转换,或者是遍历。
TLB和Cache并行查找
Cache 存的是物理地址,但是按照page offset来索引(这部分物理和虚拟是一样的)。另外一边TLB去做翻译,最后用Cache中定位的完整tag和TLB翻译的结果对比。
这种情况我觉得可以称为:page-offset Index, PPN Tag Cache。但是它的统称叫做:Virtual Index Physical Tag Cache。其实也对,因为我们没必要总是拿page-offset去index,VA里的其他bit也可以,只是拿后面的不容易造成冲突吧(根据局部性原理?)。
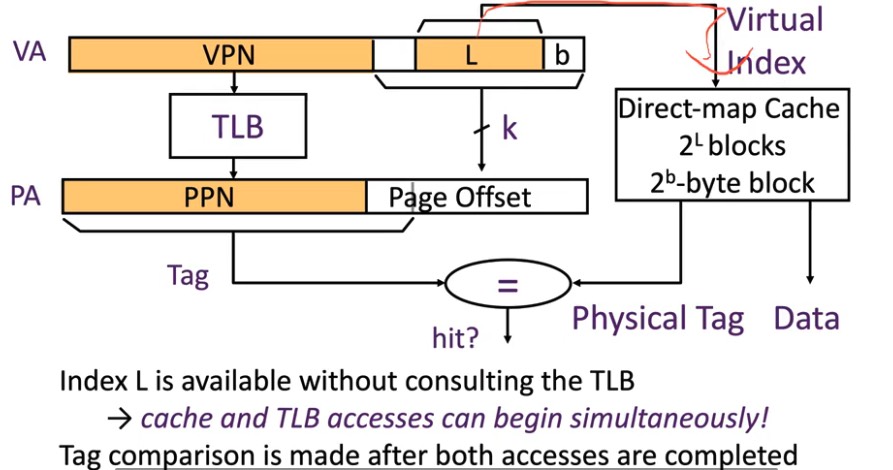
这种VIPT的Cache可以解决 cache coherence 的问题,因为有物理的Tag。