性能测量
当估计实际程序的性能优化效果时,不建议去除系统中的不确定性行为。 任何性能分析功能——包括采样,都应该在与实际部署最接近的系统下进行。
测量开销是生产环境监控的一个重要问题。由于任何监控都会影响正在运行的服务的性能,因此应该使用尽可能轻量的性能剖析方法。论文(Renet al.,2010)中提到,“如果对正在提供真实服务的服务器进行持续的性能剖析,极低的性能开销是至关重要的”。通常可以接受总体不超过1%的开销,减少监控开销的办法包括限制被监控的机器数量和使用更小的监控时间间隔。
经典的递归计算斐波那契数列,是测量性能的一个好用例。
强烈建议不能只进行一次测试,而是多次运行基准测试,这样基线程序有N个测量值,改动过的程序也有N个测量值。我们需要比较两组测试结果以确定哪一个程序更快。这本身就是一项很难处理的工作,在很多情况下,我们会被测量数据误导而得出错误的结论。如果你向任何数据科学家征求意见, 他们都会告诉你不能依赖单一指标(如最小值、均值、中位数等), 画出分布图是一种更好的方法。
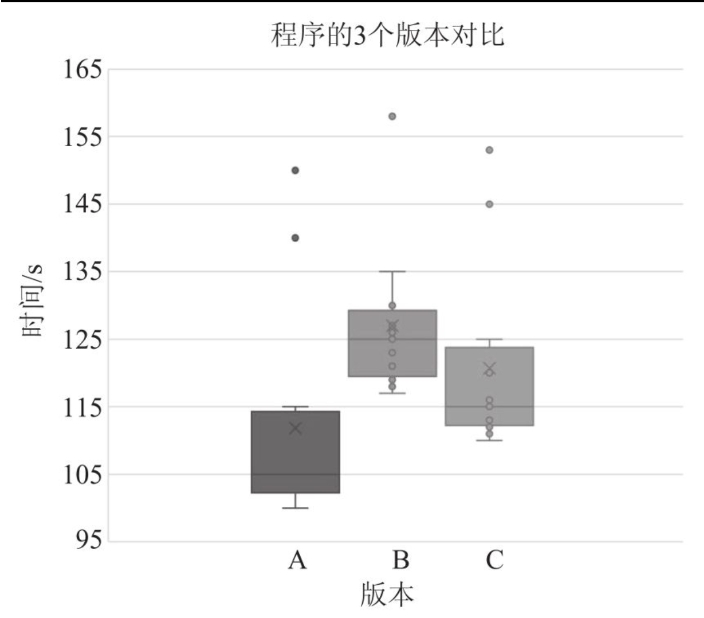
由于测量的不稳定性,调试性能通常比调试功能更为困难。
Cpu微架构
流水线的灵感来自汽车装配线,将指令的处理分为几个阶段: 取指、译码、执行、访存、回写。几个阶段并行运行。
理想情况下,启用N级流水线后,机器的指令执行效率提升N倍。 实际会存在流水线冒险,包括结构冒险、数据冒险和控制冒险。
乱序执行主要用于避免因依赖引起的停顿而导致CPU资源利用率不足的问题。 指令的动态调整通过硬件结构(如计分板)和诸如寄存器重命名技术实现。
超变量:一个时钟周期内可以发射多条指令。TODO:什么是发射? 发射宽度是在同一个时钟周期内可以发射的最大指令数。 目前Cpu的典型发射宽度为2~6。
Intel Itanium等架构使用一种称为超长指令字(Very Long InstructionWord,VLIW)的技术, 将调度超标量和多执行单元处理器的负担从硬件转移到编译器。 它的基本原理是要求编译器选择正确的指令组合使得机器被充分利用, 从而简化硬件。编译器可以使用软件流水线、 循环展开等技术来发掘更多的ILP机会, 因为硬件受制于指令窗口长度的限制,而编译器可以获得全局信息。
Cache写操作
在缓存中处理写操作更困难,CPU会使用不同的技术来处理这种复杂情况。 软件开发人员应该特别注意硬件支持的缓存写操作的流程,以确保代码性能最佳。
两种处理Cache写入命中的情况:
- 写直通(Write-Through);写入Cache立即同步到低层次的存储结构。
- 回写(Write-Back);写Cache当前只修改Cache,设置脏位。 推迟同步操作到该CacheLine被替换出Cache时。
两种处理Cache写入未命中的情况:
- 写分配(Write-Allocate);先把该位置的数据加载到Cache, 在执行上方写命中的流程。
- 写未分配(No-Write-Allocate);不使用Cache,直接对低层次存储进行修改。
性能分析中的术语
指令和数据都可能发生缓存未命中。根据TMA分析方法(见6.1节), 指令缓存未命中被归类为前端停滞,数据缓存未命中被归类为后端停滞。 当获取指令时发生指令缓存未命中,会被归类为前端问题。
性能分析【指标】
性能指标:
- IPC:IPC=INST_RETIRED / CPU_CYCLES,IPC并不能单独判断 是否性能比较好,比如说在某个处理器上,前端最多一个Cycle发射4 条指令,那么IPC是不是越接近4越好呢?其实不是,还要结合CPU 此时正在做什么事情,如果是死循环,那么就不代表什么。
- Pipeline Stalls
- Stall Front-end rate=STALL_FRONTEND/CPU_CYCLES
- Stall Back-end rate=STALL_BACKEND/CPU_CYCLES
- Frontend Bound
- ITLB events
- I-Cache events
- Backend Bound
- DTLB events
- Memory System related events
- D-Cache events
- Retiring
- Instruct Mix
- Bad Speculation
- Branch Effectiveness events
性能分析方法
性能的问题可能出在前端,称为前端Stall,在后端时则称为后端Stall。
程序运行时硬件和软件都可以采集性能数据,这里的硬件是指运行程序的CPU,软件是指操作系统和所有可用于分析的工具。通常软件栈提供上层指标,比如时间、上下文切换次数和缺页次数,而CPU则可以观察缓存未命中、分支预测错误等。根据要解决的问题,各指标的重要程度是不一样的。所以,并不是说硬件指标总能给我们提供更准确的程序执行信息。有些指标是CPU提供不了的,比如上下文切换次数。一般,性能分析工具—比如Linuxperf,可以同时使用来自操作系统和CPU的数据。
代码插桩
代码插桩通过在程序中插入额外的代码来采集运行时信息。 代码清单6展示了最简单的代码插桩例子, 即在函数开头插入printf语句以统计函数的调用次数。
基于插桩的剖析方法常被用在宏观层次,而不是在微观层次。在优化大段代码的场景,使用该方法通常会给出很好的洞察结果,因为你可以自上而下(先在主函数插桩,然后再往被调用函数插桩)地定位性能问题。
代码插桩并不能提供任何关于代码如何从操作系统或CPU角度执行的信息。例如,它不能提供进程调度执行的频率(可从操作系统获得)或发生了多少次分支预测错误(可从CPU获得)的信息。
这种方法的缺点是,每当需要插桩新内容(比如另一个变量)时,都需要重新编译。这可能会成为工程师的负担,增加分析时间。然而,这还不是唯一的缺点。因为通常情况下,你关心的只是应用程序中的热路径,所以你只需要在代码的性能关键部分插桩。在热点代码中插入插桩代码可能会导致整个基准测试的速度降低为原来的1/2[3]。此外,通过插桩代码,你可能改变程序的行为,所以可能无法看到与之前相同的现象。
这就是为什么工程师们现在不经常手动插桩代码了。然而, 自动化代码插桩仍然被编译器广泛使用。编译器能够自动对整个程序进行插桩,并收集与运行相关的统计信息。 最广为人知的用例是代码覆盖度分析和基于剖析文件的编译优化(见7.7节)。
在讨论插桩时,有必要讨论一下二进制插桩方法。二进制插桩背后的思想也类似,不过是在已经构建的可执行文件上完成的,而不是在源代码上完成。二进制插桩有两种类型:静态插桩(提前完成)和动态插桩(在程序执行时按需插入插桩代码)。
跟踪
跟踪在概念上与代码插桩非常相似,但又稍有差别, 代码插桩假设开发者可以掌控程序的代码。然而,跟踪依赖于程序现有的插桩,
负载表征
PMU有两种使用方式:计数和采样。计数模式用于负载表征, 而采样模式用于寻找热点。
人们经常用“剖析”(Profiling)来形容技术上所讲的采样。 剖析是一个更广泛的术语,包括各种收集数据的技术,例如中断、代码插桩和PMU。
采样
采样可以在两种不同的模式下进行,即用户模式采样和基于硬件事件的采样(Event-ased Sampling,EBS)。 用户模式采样是一种纯软件方法,它将代理库嵌入被分析的应用程序中。 代理库为应用程序中的每个线程设置OS计时器,在计时器计时完成时, 应用程序会接收到SIGPROF信号,该信号由收集器处理。 EBS使用硬件PMC触发中断。
用户模式采样比EBS产生更多的运行时开销。当使用10ms的默认采样间隔时,用户模式采样的平均开销约为5%。当采用1ms的采样间隔时,EBS的平均开销约为2%。因为可以以更高的频率收集样本,所以通常EBS更准确。
静态性能分析
静态性能分析器不运行实际代码而是模拟代码运行。静态准确地预测性能几乎是不可能的,因此这种类型的分析有很多限制。
- 首先,不可能静态分析C/C++代码的性能,因为我们不知道它将被编译成什么样的机器码。因此,静态性能分析更适用于汇编代码。
- 其次,静态分析工具模拟负载而不是执行负载。这个过程显然会很慢,所以我们不可能静态分析整个程序。用户只能选择一些特定的汇编指令(通常是小循环)进行分析,所以静态性能分析的应用范围很窄。
静态分析工具的输出相当底层,有时会将执行过程分解到CPU周期。开发者通常利用这些信息对关键代码区域(与CPU周期相关性比较强)进行细粒度调整。
这种工具的好处是不需要拥有真正的硬件就可以模拟不同CPU代系的代码。另一个好处,是无须担心结果的一致性:静态分析工具将始终提供稳定的输出,因为模拟不会有任何偏差(与在真实硬件上执行时相比)。静态工具的缺点是它们通常无法预测和模拟现代CPU中的所有内容:它们使用的某些模型中可能存在错误和限制。静态性能分析工具有IACA[23]和llvm-ca[24]。
编译器优化报告
编译器提供了性能优化报告,开发者可以使用这些报告进行性能分析。 有时,我们想知道某个函数是否被内联,或者某个循环是否被向量化、展开等。如果循环被展开,展开因子是多少?一种比较困难的分析方法是分析生成的汇编指令。但是,并不是所有人都喜欢阅读汇编代码。如果函数比较大,这可能会特别困难,因为可能会调用其他函数或者包含许多同样被向量化的循环,甚至包含编译器创建的同一循环的多个版本。幸运的是,包括GCC、ICC和Clang在内的大多数编译器都提供了优化报告,供开发者检查编译器对特定代码段做了哪些优化。
性能分析工具 Perf
# Counting
perf stat -e <event list>
# Event based sampling
perf record -e <event list>
# SPE sampling
perf record -e árm_spe_0/ts_enable=1'